Bionl is now Pan.bio: An end-to-end platform for the genomic era
Bionl is now Pan.bio. A new name for the end-to-end genomics platform built to move across functions, institutions, and populations.

Today, Bionl becomes Pan.bio. A new vision to match the platform we've built and the scope of the work ahead.
A multi-omics analysis platform, end-to-end
Bionl began with a precise idea: make genomic analysis more accessible by letting scientists query their data in natural language, without command lines or custom scripts. That product worked. Researchers, clinicians, and lab teams loved it, and we grew with them.
Over the last few years, we've extended the platform layer by layer:
- AI-enabled notebooks for exploratory and collaborative analysis
- Bioinformatics pipelines for reproducible, scalable processing from raw reads onward
- Variant interpretation that bridges variant calls and clinical meaning
- Cohort infrastructure that lets hospitals and data providers commercialize disease-specific patient populations securely and compliantly
Each module was built to solve a problem we saw researchers and institutions wrestling with directly. Together, they form something more than the sum of the parts: a single environment that takes genomic work from raw sequence to scientific or clinical insight without seams between the layers.
That's what Pan.bio names.
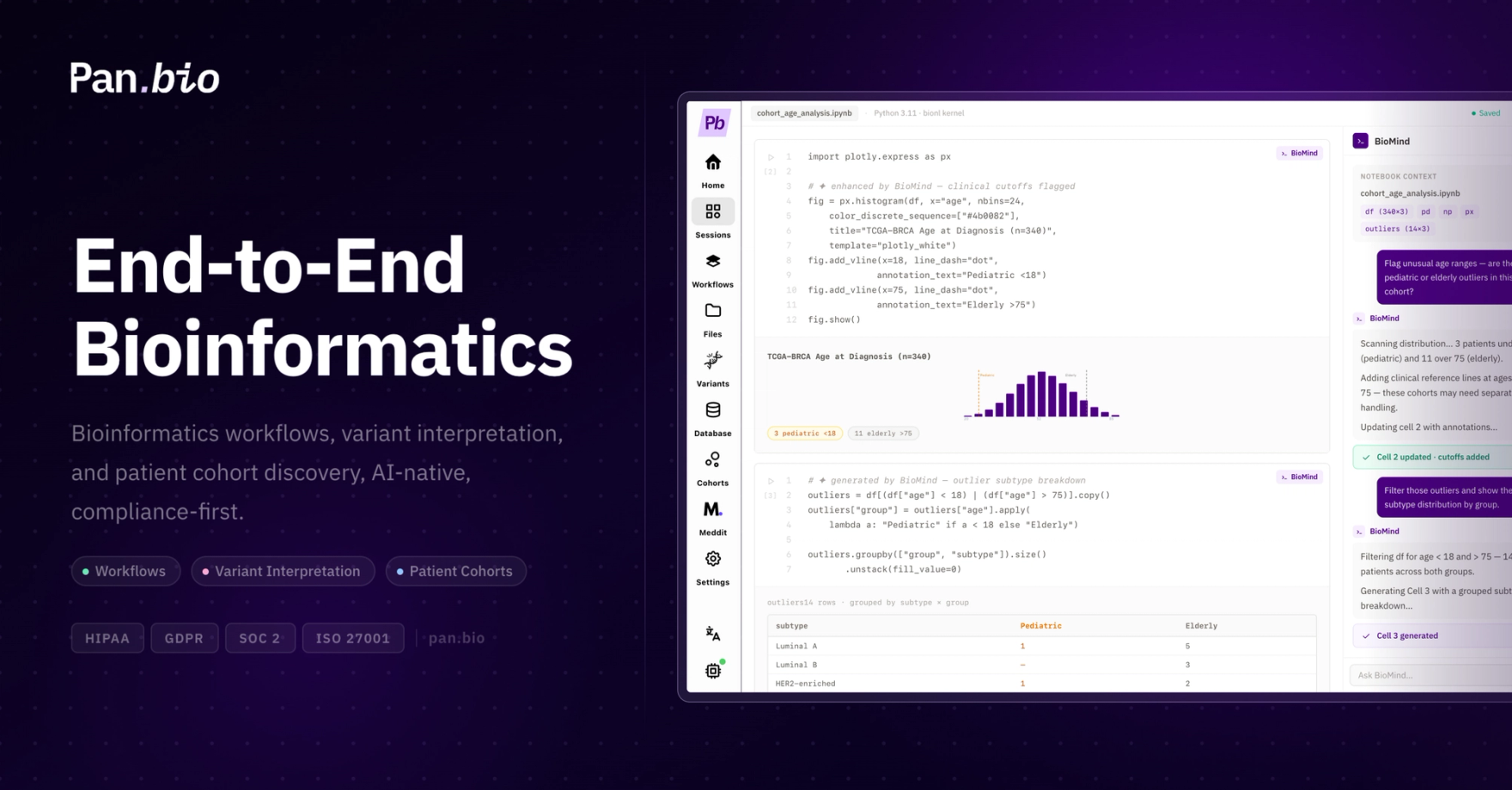
Why Pan.bio:
Pan means all, whole, across. The name reflects three commitments built into the platform.
Across bioinformatics functions. From raw FASTQs through alignment, variant calling, annotation, interpretation, and reporting, the workflow runs in one environment. Bioinformatics, clinical genomics, AI tooling, and infrastructure stop being separate categories with separate tools, because the scientists using them never experienced them as separate problems.
Across institutions and geographies. Hospitals, research centers, pharma R&D groups, diagnostic labs, and government health systems operate under different regulatory regimes, with different data-residency requirements, in different languages. Pan.bio is designed to work across them, rather than serving one well and forcing the rest to compromise.
Across populations. A genomics platform that performs well only on a narrow slice of human ancestry is, by definition, an incomplete platform. Reference databases the field has built on still over-represent European-ancestry genomes. We're engineering for the populations our customers actually serve, not just the ones that anchored the references of the last twenty years.
"Pan.bio means everything, end-to-end, across bio. We support researchers, biologists, and scientists accelerating their bioinformatics from raw data to insight, and way beyond."
The work the name describes
The physical layer of biology has been industrialized at remarkable speed. Sequencing instruments, reagents, and laboratory automation have turned DNA sequencing from a research craft into routine infrastructure, and the volume of genomic data now available is the direct consequence.
The digital layer is where the work is. Once a sample is sequenced, the meaningful steps still happen across a patchwork of bespoke configurations: alignment, variant calling, annotation, interpretation, reporting, clinical integration, and feedback into research. Every institution rebuilds similar workflows. Every handoff between bioinformatics and the clinic loses something. The science is modern; much of the plumbing isn't.
This is the gap Pan.bio exists to close. AI is finally capable enough to do meaningful work inside scientific and clinical pipelines, and the surrounding infrastructure (secure, compliant, performant, and designed for diverse institutions and populations) is what makes that capability usable in practice.
What's changing, and what isn't
The name and the URL are changing. Bionl.ai becomes Pan.bio.
Your account, data, pipelines, integrations, API keys, and pricing are exactly as they were yesterday. There's nothing to re-sign, re-configure, or migrate. The team you work with is the same team. A rebrand should be visible from the outside and invisible from the inside, and that's what we've designed for.
What's ahead
The rebrand is the lighter part of the work. The harder and more interesting work is the platform itself: extending what end-to-end genomics looks like when AI, secure infrastructure, and clinical-grade interpretation are built into a single system rather than stitched together after the fact.
That work is well underway. The new name simply describes it accurately.

- Scientist Spotlight
The Science of What We Inherit: A Conversation with Prof. Rana Dajani
Prof. Rana Dajani led the first genome-wide association study on Middle Eastern populations and discovered the first evidence of intergenerational epigenetic inheritance of trauma.
- Genomics
Your Genome Was Never in the Study, Only 1 in 600: Why Arab DNA Is the Biggest Blind Spot in Modern Medicine
Arab genetic architecture is its own genomic landscape, shaped by thousands of years of a unique demographic history, geographic isolation, and cultural practices that have no real parallel in the populations that dominate global genomic databases.
- nf-core
Democratizing Genomic Research: nf-core and the Power of No-Code, Reproducible Pipelines
This article explores the importance of nf-core pipelines in modern bioinformatics, breaking down how they enable reproducible, standardized, and scalable genomic data analysis.